Bi-LoRA: Efficient Sharpness-Aware Minimization for Fine-Tuning Large-Scale Models
 Bi-LoRA: Efficient Sharpness-Aware Minimization for Fine-Tuning Large-Scale Models
Bi-LoRA: Efficient Sharpness-Aware Minimization for Fine-Tuning Large-Scale ModelsOverview
Bi-LoRA targets the problem of fine-tuning large pre-trained models under data scarcity, where generalization is often fragile. Sharpness-Aware Minimization (SAM) is known to enhance generalization by explicitly seeking flat minima, but its standard formulation requires additional forward-backward passes and full-parameter perturbations, which are expensive for large-scale models.
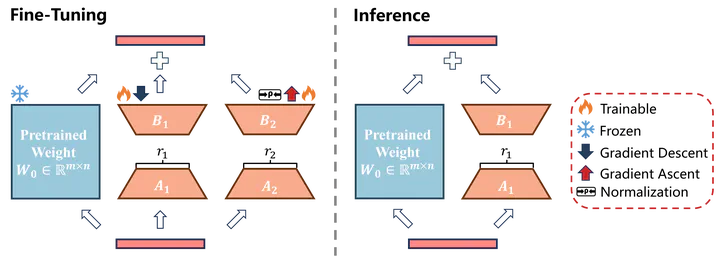
To combine the benefits of SAM with the efficiency of LoRA-style low-rank adaptation, the paper proposes Bi-directional Low-Rank Adaptation (Bi-LoRA). Bi-LoRA uses two coupled LoRA modules: a primary one for standard task adaptation and an auxiliary adversarial one that captures SAM’s perturbation direction, allowing the model to enjoy sharpness-aware optimization while remaining memory- and compute-friendly.
Key Contributions
- Bi-directional Low-Rank Adaptation (Bi-LoRA): Introduces a new parameter-efficient fine-tuning scheme with two LoRA modules: a primary LoRA branch updated by gradient descent and an auxiliary adversarial LoRA branch updated by gradient ascent to model SAM perturbations in a low-rank form.
- Decoupling optimization and perturbation: Separates SAM-style adversarial perturbations from the main LoRA optimization, avoiding the restriction of sharpness optimization to a single low-rank subspace and enabling exploration of a broader neighborhood in parameter space.
- Efficiency improvements over standard SAM: The dual-module design allows simultaneous task optimization and perturbation, eliminating the doubled training cost of vanilla SAM while retaining its generalization benefits, which is critical for large models.
- Empirical validation on large-scale fine-tuning: Experiments across various architectures and tasks demonstrate that Bi-LoRA consistently improves generalization and training efficiency compared to baseline LoRA fine-tuning and SAM-based alternatives.
Method
The method starts from the observation that directly applying SAM to LoRA parameters operates in a restricted low-rank subspace, which weakens the ability to approximate the full-parameter sharpness of the loss landscape. To address this, Bi-LoRA introduces a bi-directional mechanism:
- A primary LoRA module is trained with standard gradient descent to adapt the pre-trained model to the downstream task using a small number of additional parameters.
- An auxiliary adversarial LoRA module is trained in the opposite direction (gradient ascent) to approximate the adversarial perturbation required by SAM, but in a low-rank form attached to the same base model.
During training:
- The auxiliary LoRA branch estimates an adversarial direction that approximates the worst-case loss increase in a local neighborhood, in the spirit of SAM but represented through low-rank updates.
- The primary LoRA branch is updated to minimize the loss under this perturbation, effectively steering optimization toward flatter regions of the loss landscape.
- Because both branches are parameter-efficient and can be updated within a single training loop, Bi-LoRA keeps memory and compute overhead manageable while reproducing the benefits of sharpness-aware training.
This design allows Bi-LoRA to bridge SAM and LoRA: it preserves the parameter-efficient nature of LoRA, while introducing a principled, low-rank realization of SAM’s adversarial perturbation to improve generalization in large-scale fine-tuning.