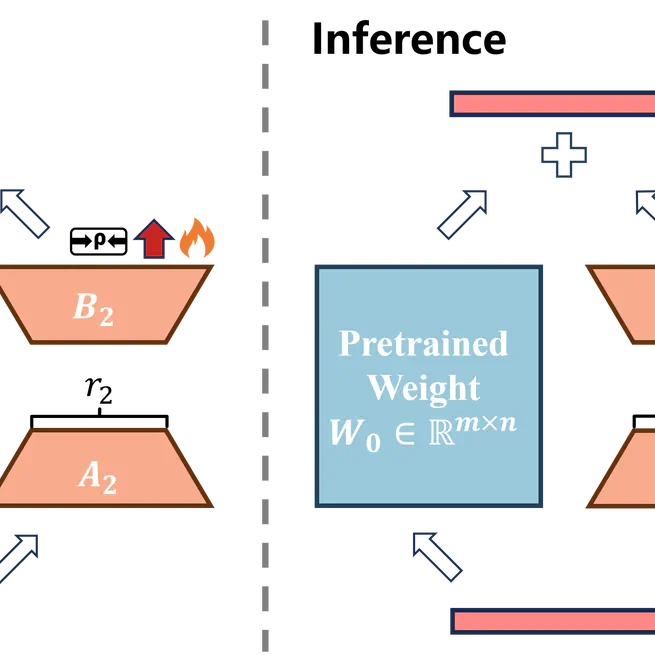
Bi-LoRA: Efficient Sharpness-Aware Minimization for Fine-Tuning Large-Scale Models
Bi-LoRA introduces an auxiliary adversarial LoRA module to integrate sharpness-aware minimization into parameter-efficient fine-tuning, enabling flatter minima, better generalization, and SAM-like benefits for large-scale models without incurring the usual memory and computation overhead.
Aug 27, 2025

T2I-ConBench: Text-to-Image Benchmark for Continual Post-training
This work introduces T2I-ConBench, a unified benchmark for continual post-training of text-to-image diffusion models, covering item customization and domain enhancement and assessing methods on generality retention, target-task performance, forgetting, and cross-task generalization through an automated pipeline that combines standard metrics, human-preference modeling, and vision-language QA.
May 22, 2025
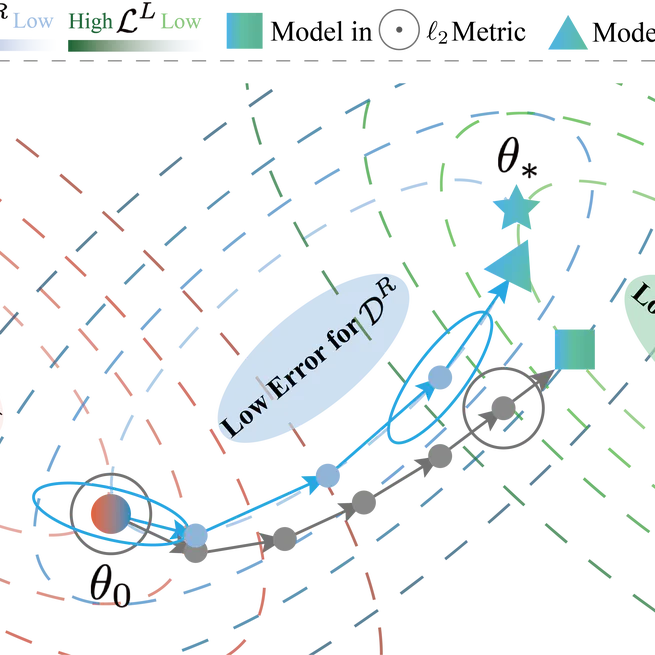
A Unified Gradient-based Framework for Task-agnostic Continual Learning-Unlearning
This paper proposes a unified gradient-based framework for task-agnostic continual learning-unlearning that models continual learning and machine unlearning within a single KL-divergence-based optimization objective, decomposes gradient updates into interpretable components, and introduces a Hessian-informed remain-preserved manifold and the UG-CLU algorithm to balance knowledge acquisition, targeted unlearning, and stability across benchmarks.
May 21, 2025
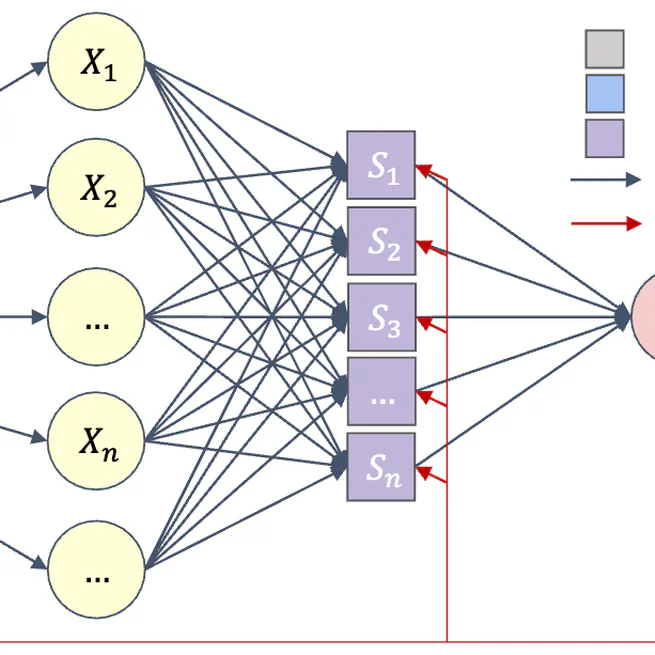
Online Continual Learning via Logit Adjusted Softmax
This paper theoretically analyzes that inter-class imbalance is entirely attributed to imbalanced class-priors, and the function learned from intra-class intrinsic distributions is the Bayes-optimal classifier, and presents that a simple adjustment of model logits during training can effectively resist prior class bias and pursue the corresponding Baye-optimum.
May 29, 2024
Query Attack by Multi-Identity Surrogates
QueryNet is a attack framework that reduces queries by averagely about an order of magnitude compared to alternatives within an acceptable time, according to comprehensive experiments 11 victims on MNIST/CIFAR10/ImageNet, allowing only 8-bit image queries, and no access to the victim’s training data.
Mar 12, 2023
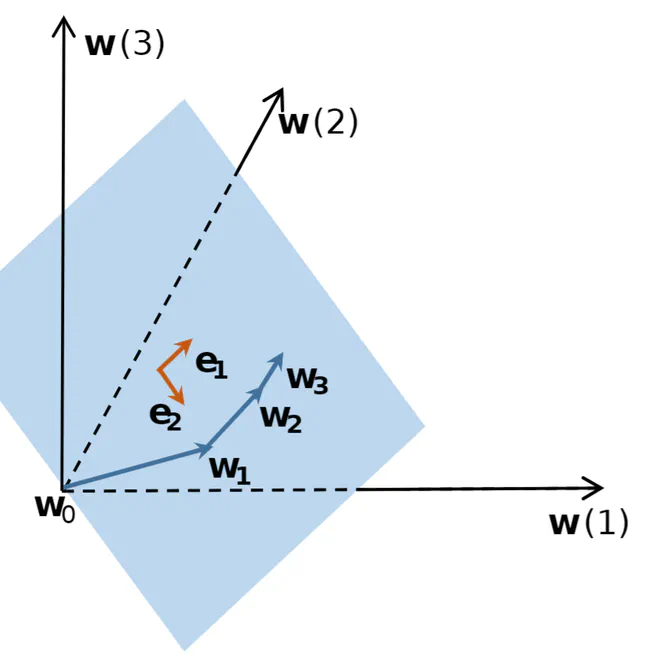
Low Dimensional Trajectory Hypothesis is True: DNNs Can Be Trained in Tiny Subspaces
This paper develops an efficient quasi-Newton-based algorithm, obtains robustness to label noise, and improves the performance of well-trained models, which are three follow-up experiments that can show the advantages of finding such low-dimensional subspaces.
May 26, 2022