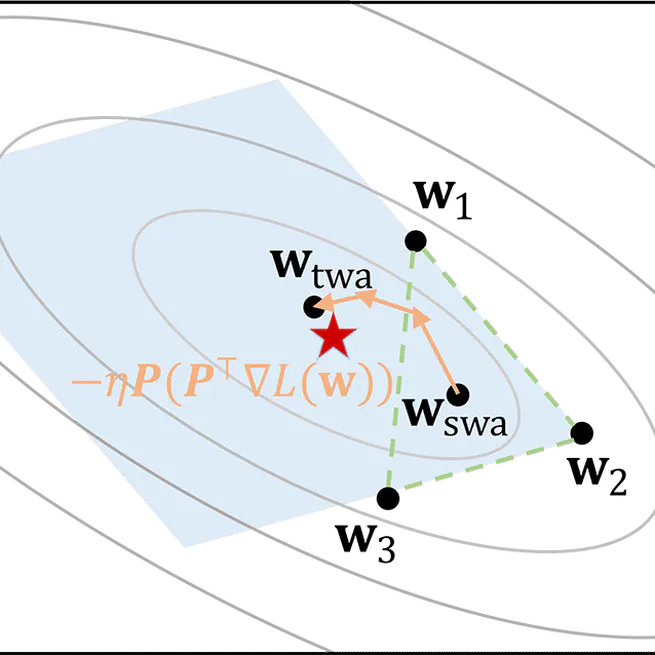
Trainable Weight Averaging: Efficient Training by Optimizing Historical Solutions
A parallel framework for large-scale training with efficiency in memory and computation is designed for TWA or EMA and manifests better adaptation to different stages of training.
Feb 26, 2023
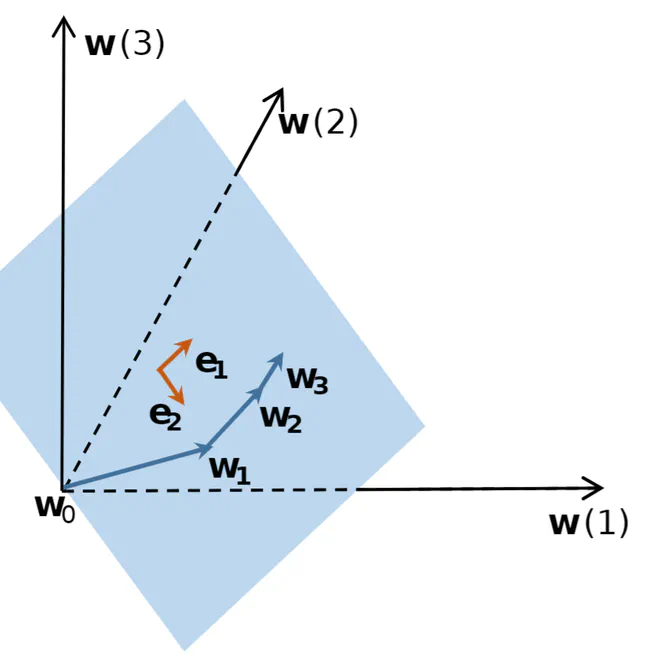
Low Dimensional Trajectory Hypothesis is True: DNNs Can Be Trained in Tiny Subspaces
This paper develops an efficient quasi-Newton-based algorithm, obtains robustness to label noise, and improves the performance of well-trained models, which are three follow-up experiments that can show the advantages of finding such low-dimensional subspaces.
May 26, 2022